



电子图书馆借还及查询系统(MVC,Struts,MySQL)(18000字)
摘 要
随着科学技术的进步,计算机行业的迅速发展,大大提高人们的工作效率。计算机信息处理系统的引进已彻底改变了许多系统的经营管理 。
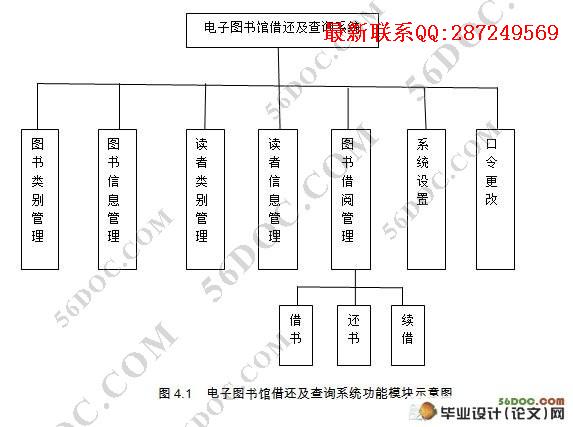
图书馆管理系统是社区管理机制中的重要组成部分,通过对图书管理系统的运行管理机制进行调查研究,开发了此图书系统。本系统中解决了社区图书管理事务中的常用基本问题以及相关统计工作。本系统中包含6个功能模块:系统设置,读者管理,图书管理,图书借还,系统查询和更改口令。
本系统使有JSP进行网页界面的设计,使用MVC设计模式,采用了开源框架Struts,它采用了当今软件设计的最新技术,具有开发效率高、设计灵活、生成的软件界面友好美观等特点。本系统中通过JDBC驱动和数据库进行无缝连接,后端的数据库是mysql,也是一个开源的数据库系统,该数据库具有较高的完整性,一致性和安全性。
关键词:图书管理,JSP,Struts,Mysql
ABSTRACT
With the progress of science and technology, the rapid development of the computer industry has been improving people's working efficiency greatly.The introduction of computerized information processing system has sharply changed the management in many systems in many fields.
The management system of the library takes an important role in the administration of community organization. I desigen the system after the thorough investigations about the library management system’s mechanism. This system contains with reader informantion management model, book information management model, book borrowing and returning , system information querying and password setting.
The system is contrived with JSP as well as Struts,the software design mode of MVC with open source framework techonolege, which makes this system have the advantages of efficiently designed with beauteous and friendly interface . This system use jdbc driver to connect the mysql database server,which is also an open source database system for its users. The batabase was desigend with highly integrity, security, and consistency.
Keywords:Books management,JSP,Struts,Mysql
功能需求分析
电子图书借还及查询系统的主要任务是实现迅速检索查询,方便借阅归还图书,使图书管理员高效的完成系统的各项基本操作,系统管理员是管理用户设置权限等操作。因此电子图书借还及查询系统要完成一下功能:
1. 图书类别信息管理:作为一个社区的图书馆,涉及到的图书是很多的,这就有必要对图书进行分门别类,这样有利于对图书的查询和管理。不同的图书类别可以借阅的天数也是不一样的,管理员登陆系统后可以对图书类别进行添加,更新和删除操作。
2. 图书信息管理:当管理员对图书类别信息添加完成后,就可以开始进行图书信息的录入了。
3. 读者类别管理:为了方便图书馆的管理,系统对读者的类别进行了分别,不同的读者类别可以借阅图书的数目是不一样的。管理员在登陆系统后可以这个读者类别信息进行管理,包括添加读者类别信息,修改读者类别,删除读者类别,特别是执行删除操作时需要保持数据库表数据之间的一致性。
4. 读者信息管理:当管理员把读者类别信息编辑好完成后,就可以办理读者信息了,管理员可以添加新的读者信息,修改已经存在的读者信息,删除读者信息。
5. 图书借阅管理:读者可以登陆系统查询自己喜欢的图书,然后到图书馆进行图书借书的登记操作,当读者看完了书或需要归还时,需要拿着自己的图书到图书馆进行归还,此时有管理员办理图书归还业务。当然,如果读者借阅了图书因某种原因忘记了归还,管理员还可以对这些信息进行统计,同时,管理员还可以对已经出借的图书进行续借的办理。
6. 系统设置: 管理员登陆系统后可以修改图书馆的信息,可以修改管理其他操作员的信息,可以管理书架信息。
7. 口令更改:管理员登陆系统后,都可以对自己的登陆密码进行修改操作,这样保证了系统的安全性。
系统开发平台和工具
工具名称 用途
JDK 1.6.0_11
MyEclipse
MySQL 5.0
SQLYog 6.1
Tomcat 6.0
Struts 1.0 JAVA 开发工具包
J2EE集成开发环境
小型关系数据库管理系统
MySQL图形化数据库管理工具
Web应用服务器
第三方插件,可扩展的JAVA EE Web框架

#p#副标题#e#
目 录
摘 要 I
ABSTRACT II
第1章 绪论 1
1.1课题的背景 1
1.2课题的意义 1
第2章 系统开发平台及技术 3
2.1 JAVA的网络功能与编程 3
2.1.1 JAVA语言简介 3
2.1.2 JAVA语言在网络上的运用 3
2.1.3 Servlet技术简介 4
2.2 Struts概述 5
2.1.1 Struts的由来和发展 5
2.2.2 Struts的优缺点 6
2.2.3 Struts的工作流程 7
2.2.4 MVC简介 7
2.3 WEB服务器和数据库 8
第3章 系统需求分析 9
3.1 功能需求分析 9
3.2 性能需求分析 10
3.2.1 安全性要求 10
3.2.2 精度要求 10
3.2.3 界面需求 10
3.2.4 输入输出要求 10
3.3 数据需求分析 10
3.4 可行性分析 11
3.4.1 技术可行性分析 11
3.4.2 经济可行性分析 12
第4章 系统总体设计 13
4.1设计思想 13
4.2 系统目标 13
4.3 系统组成 14
4.4 数据库设计 14
4.5 数据表的结构表 14
第5章 系统详细设计 20
5.1 程序设计概述 20
5.2 数据库与Web服务器的连接 20
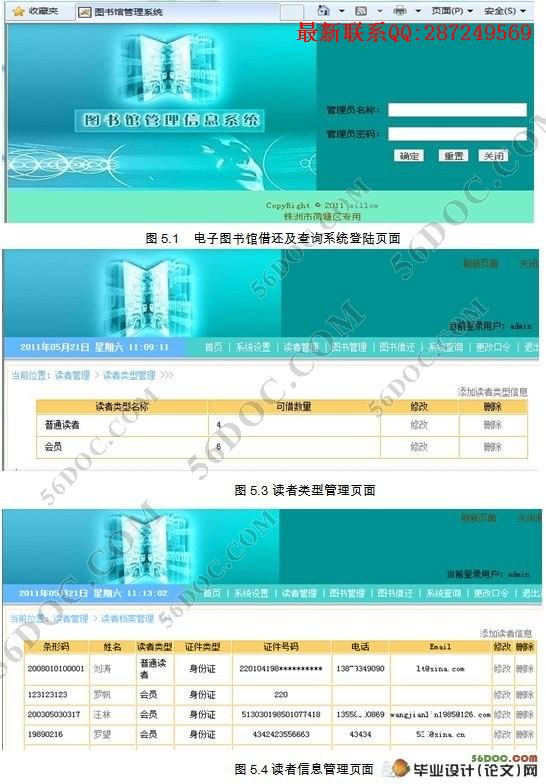
5.3 登陆模块程序设计 21
5.4 读者管理功能模块的实现 22
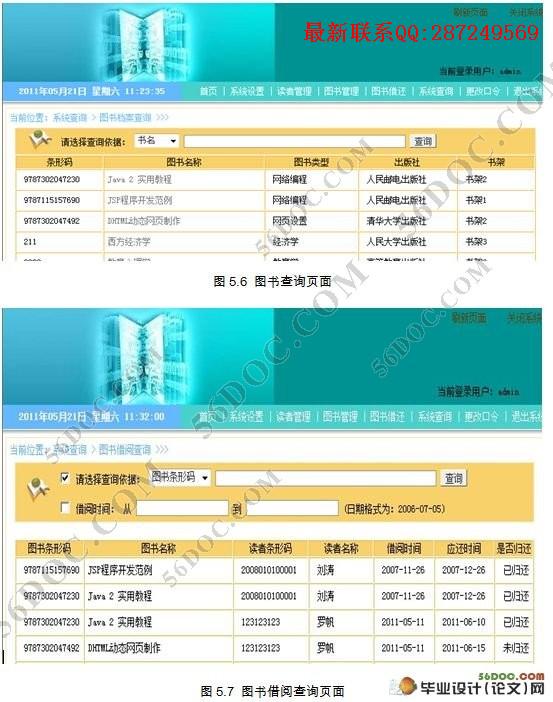
5.5 查询功能模块的实现 24
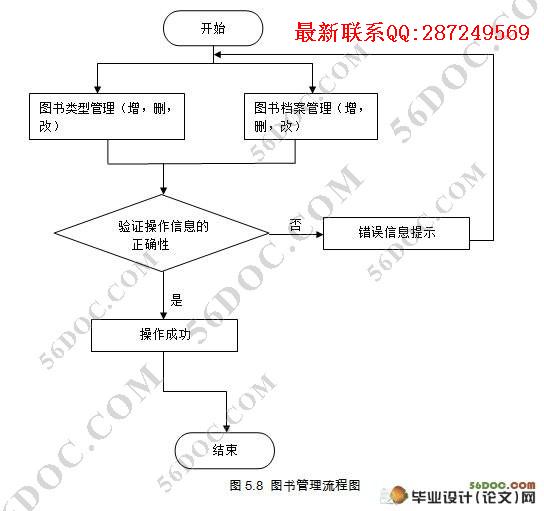
5.6 图书管理功能模块的实现 27
5.7 图书借还功能模块的实现 28
第6章 系统测试 33
6.1 软件测试的方法与步骤 33
6.2 测试用例设计与测试用例的运行过程及测试结果分析 34
6.2.1 模块测试 34
6.2.2 集成测试 38
6.2.3 验收测试 38
6.3 评价 38
结 论 39
参考文献 40
附 录 41
致 谢 43
